One of the factors of The Twelve-Factor App methodology is Store config in the environment.
Keeping your configuration separate from your code, rather than hard coding stuff, is sound advice. But in order to follow it, you need to understand what configuration is. The twelve-factor "manifesto" explains
"An app’s config is everything that is likely to vary between deploys (staging, production, developer environments, etc)"
and then goes on to list examples such as connections strings and credentials to databases and other external resources/services and per-deploy things like hostname to be included in aggregated logs.
What is not configuration?
The document continues with clarifying
"Note that this definition of “config” does not include internal application config, … This type of config does not vary between deploys"
In essence: thing that vary between deployments (dev/qa/stage/production; geographic region etc) and/or instances (hostname within a deployment cluster) is configuration that should be kept separate from the version controlled code, while internal configuration identical to all deployments and instances belong inside the codebase.
In this post I’m going to argue that something else isn’t configuration from a Twelve-Factor App point of view:
Things that are expected to change over time is not configuration
Well, of course, if those things also differ per deployment, they are configuration. But just because something is determined to be more or less likely to change down the road, often for non-technical reasons, doesn’t make it configuration and warrant it to be treated as such.
Even if it is expected to first change in your development environment, then in your staging environment and then finally in your production evenment, it isn’t configuration. You know something else that has the same lifecycle expectation? Your code.
Let me take as an example for you: the monthly price of a Netflix subscription. (Please note that this is completely fictitious – I don’t know how Netflix technically treats their prices.)

When Netflix launched, they likely anticipated that their prices would change at some point in the future. And when they actually did update their prices, don’t you think that they first did this in some dev/test/qa environment before they "released" the new price to the market (i.e. production environment)?
"I need a UI"
Often these kinds of things are initiated by some business stakeholders, such as the marketing people. "You need to create a UI so that we can change X [monthly price] whenever we want to". Sometimes they also want the ability to copy settings from one environment to another, either by some export/import settings feature in said UI, or by having someone set up a routine so that they can copy database entries from one environment to the other.
This should raise a red flag. If the business people want to be able to first make a "configuration" change in a qa/stage environment and then, when they think they are ready, copy that "configuration" over to the production environment, you should take a step back and contemplate about what you are trying to achieve. Are you in essence creating two parallell deployment pipelines – one for the code and one for the config? Who is going to develop and maintain the config pipeline? Can the extra cost and complexity of having two separate deployment pipelines really be motivated…?
I would say that a litmus test for whether something is truly a business only configuration warranting a UI, is that if you imagine that you stopped all development and then propagated all code so that all environments ran the exact same codebase and all the “marketing deadlines” (such as price increases) were reached and after that you had a difference in configuration between the environments – would that be considered an error? Another way to put it: If you changed this configuration in the production environment first, would there then be a need to propagate the change "backwards" to stage/qa/dev? Or is it totally fine if the Netflix subscription costs $10.99 for actual customers, $9.99 in the stage environment and $6.03 on John Doe’s development machine?
Release cadence
Instead putting "configuration" that is expected to change inside your codebase assumes that you will be releasing that codebase often enough compared to how frequently (and with how much notice) the configuration is expected to change. If your next production release is scheduled in 5 months, you’d wish you had created that UI when the business people requires that you change X at the next turn of the month.
But what if you took the time that you would have spent creating the UI and export/import feature, and instead spent that time streamlining the release pipeline of your codebase? Ultimately you’d have Continuous Delivery, so that a change made in your codebase (on a hotfix branch, if needed) could reach production within hours if not minutes.
If you release relatively often, but marketing requires that a change (such as price increase) occurs at a specific day or even time on that day, and you can’t or don’t want to release on that exact day or time, you could consider including the config in your codebase using Feature toggles. Admittedly there is overhead involved with allowing you to toggle the feature during runtime, however.
Config or data?
Sometimes the thing you want to change or add is not just a simple string or number, but an entire data structure. This still doesn’t warrant a UI and/or export/import. As for database data you could use – and hopefully you are already using – some database migration tool like Flyway or Liquibase, and you can include the config change in those scripts.
Other options include storing structured data in separate files, such as XML or JSON, alongside your source code. Maybe you can even define a file format that the business people can manage themselves, and that will then be included in the codebase? (Before you suggest that however, I should warn you they are likely to suggest Excel…)
Objections
"But that requires a developer to make a business change!"
Generally that is true – as with changes to the business logic of your application. Even though you may be able to find ways around that, as per above, this means putting this kind of config in your codebase probably won’t work well for slow moving, waterfall type of organizations. But in an agile environment with Continuous Delivery or at least a high release cadence, it shouldn’t be much of an issue unless the changes required are very frequent or complex.
And remember, we had already saved ourselves development time by avoiding having to create the UI and/or the process for separately propagating configuration from one environment to another.
Benefits
We’ve already mentioned the benefit of avoiding having to set up, document and maintain a separate "release pipeline" for your config. Consider the fact that it should often be managed by non-tech people and the benefits of avoiding it may be even greater.
Another main benefit if you integrate this type of configuration in your codebase, is that you can use lower level, cheaper/faster tests to verify the correctness of the settings. Hopefully you are familiar with the Test Pyramid, visualising that higher level tests (such as UI or integration tests) are both more expensive to maintain and runs slower, effectively slowing down your release pipeline and decreasing your maximum possible release cadence.
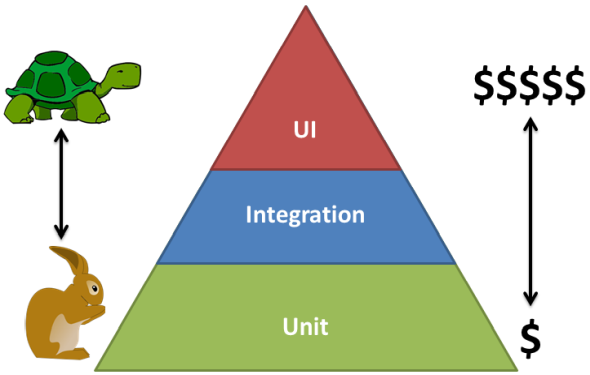
In the Netflix example, having the price inside your codebase means you can write unit tests for verifying debit calculations etc, rather than having to write for example UI tests for the same verification.
You will also get your configuration version controlled, which is a positive side effect – especially if you managed to avoid Excel. 🙂
Agree or disagree? I’d love to hear your thoughts in the comments below.




